RAG: Klíč k přesnější komunikaci s AI
Základní model komunikace s umělou inteligencí je jednoduchý – zadáte prompt a čekáte na odpověď. Tento přístup funguje dobře pro obecné dotazy, ale naráží na své limity při požadavcích na práci s aktuálními nebo specifickými informacemi. Řešením je integrace dodatečné vrstvy, která dokáže doplnit chybějící kontext. Tato metoda se nazývá Retrieval Augmented Generation (RAG) a představuje významný krok vpřed v oblasti AI aplikací.
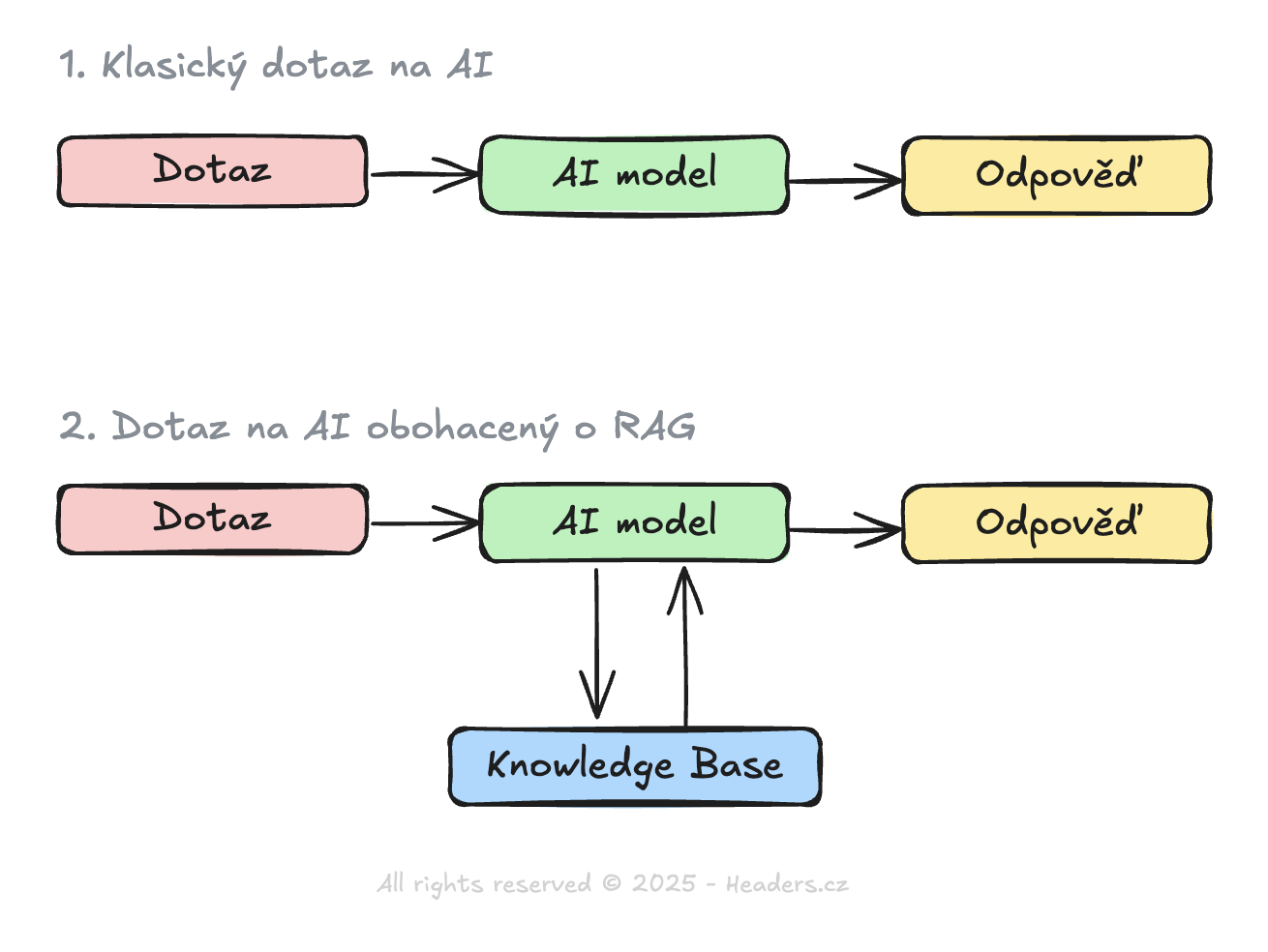
Tradiční komunikace s AI
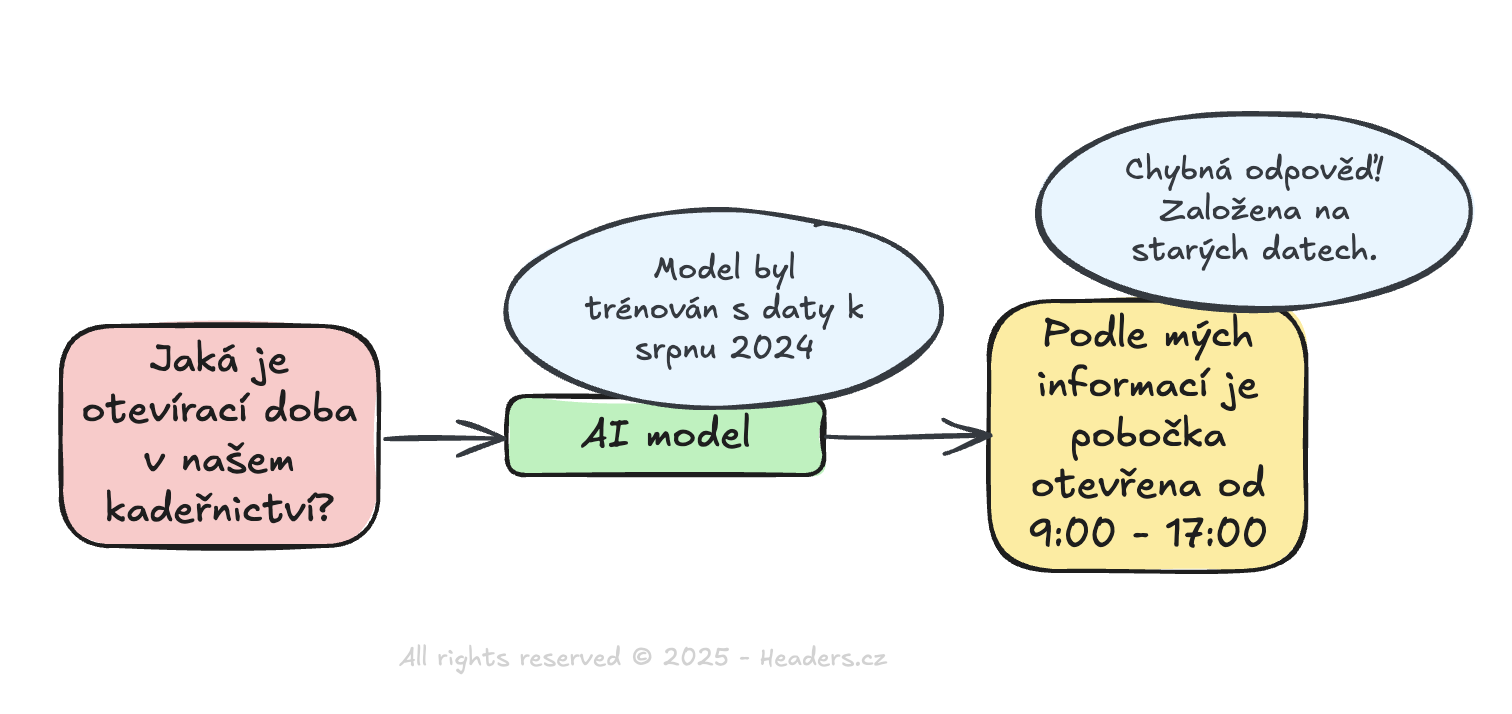
Při tradičním přístupu zadáte dotaz a AI generuje odpověď výhradně na základě znalostí získaných během tréninku. To funguje spolehlivě pro obecné otázky a úkoly, kde není potřeba aktuální nebo vysoce specifický kontext. Například při žádosti o vysvětlení historické události nebo základních principů fyziky. Avšak když potřebujete pracovat s aktuálními daty nebo specifickými dokumenty vaší organizace, tento přístup naráží na své limity.
RAG – Retrieval Augmented Generation
RAG přidává do procesu klíčový mezikrok – před generováním odpovědi nejprve vyhledá relevantní informace ve vámi definovaných zdrojích (Knowledge Base). Tento proces probíhá v několika fázích, který si ukážeme na příkladu s vektorovou databází.
1. Příprava dat
- Rozdělení dokumentů na menší části (chunking)
- Vytvoření vektorových reprezentací textu (embeddings)
- Uložení do vektorové databáze
2. Zpracování dotazu
- Převod dotazu na vektor
- Vyhledání relevantních částí dokumentů
- Spojení nalezených informací s původním dotazem
3. Generování odpovědi
- AI model využívá jak své trénované znalosti, tak nalezené relevantní informace
- Výsledkem je kontextově přesná odpověď
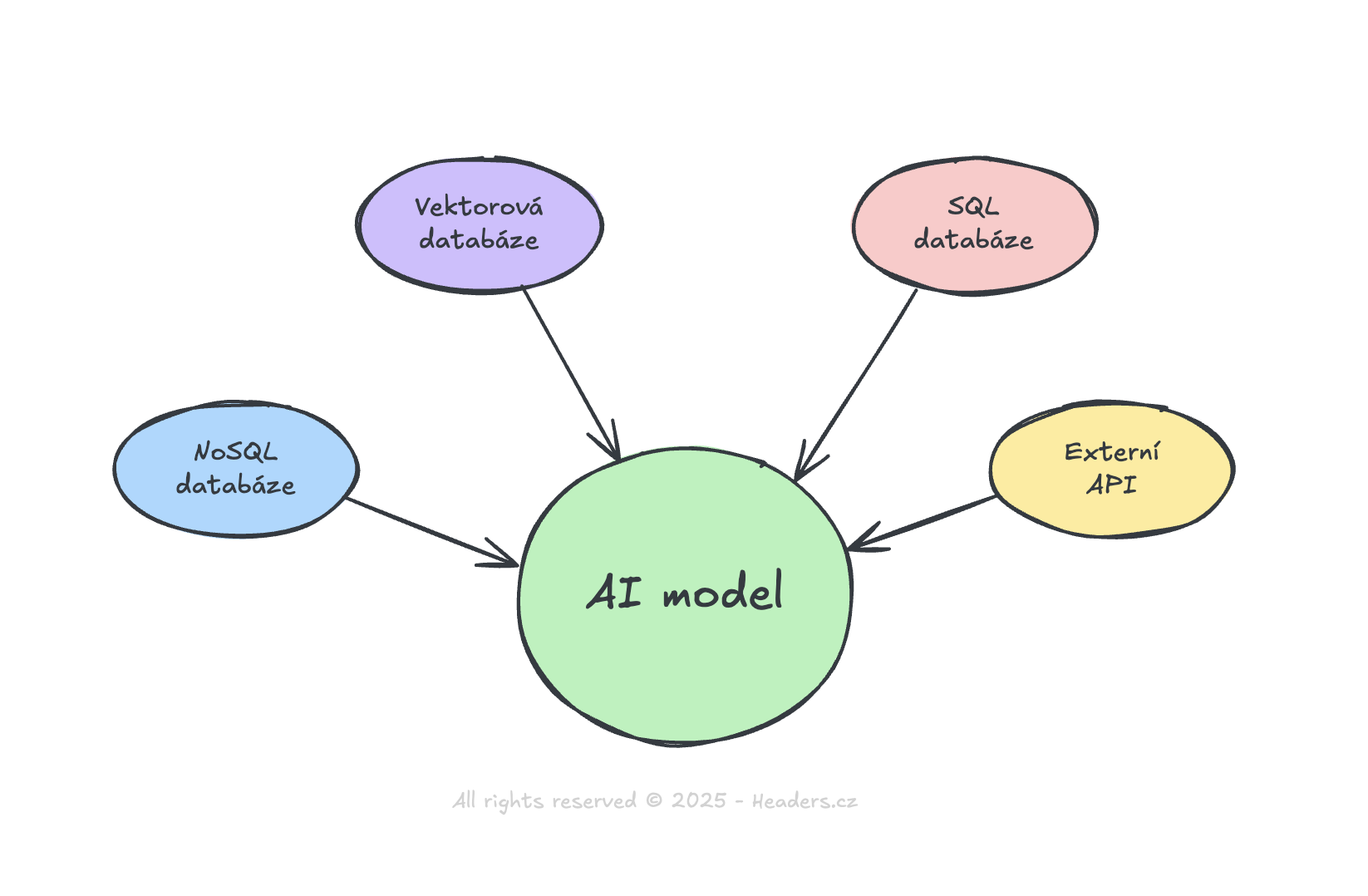
Možnosti zdrojů dat pro Retrieval
Přestože se o RAGu často mluví v souvislosti s vektorovými databázemi, retrieval fáze může využívat jakýkoliv existující zdroj dat. Ve skutečnosti organizace často začínají propojením svých AI systémů s již existujícími zdroji dat (např. data v tradiční relační databázi). Teprve později, podle potřeby, přidávají specializované vektorové úložiště.
Podívejme se na hlavní typy zdrojů dat:
Vektorové databáze
Moderní řešení jako Pinecone, Weaviate nebo Milvus jsou optimalizovaná pro vyhledávání podobnosti v textu. Fungují na principu převodu textu na číselné vektory, což umožňuje rychlé a přesné vyhledávání podobných obsahů.
Relační databáze
Pro strukturovaná data lze efektivně využít data v existujících databázích, která se zpřístupní přes API. Tento přístup je vhodný zejména tam, kde pracujete s přesně definovanými daty jako jsou produktové katalogy nebo zákaznické záznamy.
Dokumentové úložiště a NoSQL databáze
MongoDB nebo Elasticsearch vynikají při práci s nestrukturovanými daty. Jsou ideální pro rozsáhlé textové záznamy různorodé struktury, jako jsou články, dokumentace nebo zákaznická komunikace.
Externí API a služby
Pro získání aktuálních informací lze integrovat externí služby poskytující data o počasí, finančních trzích nebo zpravodajství.
Interní zdroje a legacy systémy
Existující firemní systémy lze propojit s RAG pomocí vhodných konektorů a transformací dat.
Praktické příklady využití RAG
Podívejme se na typické scénáře nasazení RAG systémů, které vycházejí z publikovaných případových studií a technických článků:
Zákaznická podpora
RAG výrazně zlepšuje schopnost AI asistentů poskytovat přesné odpovědi v kontextu konkrétních produktů a služeb. Podle studie “Retrieval-Augmented Response Generation for Large Language Models” (Wang et al., ACL 2023)1, systémy využívající RAG dosahují v průměru signifikantně vyšší přesnosti odpovědí oproti základním jazykovým modelům. Klíčové benefity:
- Automatické dohledání relevantní dokumentace k produktu
- Konzistentní odpovědi napříč různými komunikačními kanály
- Schopnost pracovat s aktualizovanými informacemi bez přetrénování modelu
Práce s firemní dokumentací
Microsoft ve své technické dokumentaci “RAG Pattern Implementation Guide” (Microsoft Azure Documentation, 2023)2 popisuje využití RAG pro práci s rozsáhlou technickou dokumentací Azure. Tento přístup umožňuje:
- Kontextově přesné odpovědi na dotazy vývojářů
- Automatické propojování související dokumentace
- Rychlé vyhledávání v aktuálních verzích dokumentů
Analýza právních dokumentů
Podle zprávy “AI in Legal Practice: Current Applications” (Stanford Law School’s CodeX center, 2023)3 se RAG stává standardem pro práci s právními dokumenty. Hlavní využití zahrnuje:
- Vyhledávání relevantních precedentů v judikátech
- Analýzu smluv a právních dokumentů
- Asistenci při právním výzkumu

Výzvy a omezení RAG
Implementace RAG systému přináší nicméně řadu výzev, které je třeba pečlivě zvážit a řešit. Podívejme se na hlavní oblasti, kterým je třeba věnovat pozornost.
Technické výzvy
Výpočetní náročnost
Zpracování velkých objemů dat klade značné nároky na výpočetní infrastrukturu. Při vytváření vektorových reprezentací (embeddings) je třeba počítat s:
- Vysokými nároky na GPU při generování embeddingů
- Potřebou škálovat výpočetní kapacitu podle objemu dat
- Optimalizací batch processingu pro efektivní zpracování
Latence systému
Vyhledávání v rozsáhlých databázích může způsobovat zpoždění:
- Každý dotaz vyžaduje vektorové vyhledávání podobnosti
- Složité dotazy mohou vyžadovat prohledávání více zdrojů
- Je třeba najít rovnováhu mezi přesností a rychlostí odpovědí
Údržba aktuálnosti
Vektorové reprezentace je nutné pravidelně aktualizovat:
- Změny v původních dokumentech musí být promítnuty do embeddingů
- Je třeba sledovat a řešit případnou degradaci kvality reprezentací
- Aktualizace musí probíhat bez výpadku služby

Kvalita dat
Příprava vstupních dat
Kvalita výstupů RAG systému přímo závisí na kvalitě vstupních dat:
- Odstranění duplicit a nekonzistencí v dokumentech
- Strukturování nestrukturovaných dat
- Standardizace formátů a kódování
- Řešení chybějících nebo poškozených dat
Chunking dokumentů
Správné rozdělení dokumentů na části je kritické:
- Příliš velké chunky mohou obsahovat irelevantní informace
- Příliš malé chunky mohou ztratit kontext
- Je třeba zachovat sémantickou souvislost částí
- Různé typy dokumentů mohou vyžadovat různé strategie dělení
Správa aktuálnosti
Zajištění konzistence a aktuálnosti vyžaduje systematický přístup:
- Vytvoření procesů pro pravidelnou aktualizaci dat
- Sledování životního cyklu dokumentů
- Verzování dokumentů a jejich reprezentací
- Řešení konfliktů při současných změnách

Integrační komplexita
Integrace datových zdrojů
Sladění různých zdrojů dat představuje komplexní výzvu:
- Různé formáty a struktury dat
- Rozdílné API a přístupové metody
- Nutnost řešit výpadky jednotlivých zdrojů
- Synchronizace dat mezi systémy
Bezpečnost a přístupová práva
Zajištění bezpečnosti je kritické zejména při práci s citlivými daty:
- Implementace granulárních přístupových práv
- Sledování a audit přístupů k datům
- Šifrování dat v klidu i při přenosu
- Řešení compliance požadavků (GDPR, atd.)
Spolehlivost systému
Zajištění spolehlivosti celého řetězce vyžaduje:
- Monitoring všech komponent systému
- Implementaci fallback mechanismů
- Strategii zálohování a obnovy
- Plán pro řešení výpadků a incidentů
Tyto výzvy nejsou nepřekonatelné, ale vyžadují pečlivé plánování a systematický přístup k jejich řešení. Správně implementovaný RAG systém může přinést významnou hodnotu i přes počáteční komplexitu implementace.
Závěr
RAG představuje významný pokrok v oblasti praktického využití AI. Kombinace trénovaných modelů s přístupem k aktuálním a specifickým datům otevírá nové možnosti pro automatizaci a zefektivnění práce. Klíčem k úspěšné implementaci je pečlivá příprava dat, výběr vhodných technologií a důraz na kvalitu celého řešení.

V Headers pomáháme firmám implementovat umělou inteligenci do jejich
systémů a procesů.
Pokud chcete vědět, jak by mohla AI posunout vaše podnikání, neváhejte nás
kontaktovat na:
Odkazy
Footnotes
-
Wang, L., et al. (2023). Retrieval-Augmented Response Generation for Large Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 1223-1234. ↩
-
Microsoft. (2023). RAG Pattern Implementation Guide. Azure Documentation. https://learn.microsoft.com/cs-cz/azure/search/retrieval-augmented-generation-overview ↩
-
Stanford CodeX. (2023). AI in Legal Practice: Current Applications. CodeX - The Stanford Center for Legal Informatics. ↩